on
Planchet: a personal assistant for processing large datasets
If you have been doing NLP in the past few years, chances are you’ve come across Matt Honibal ‘s “NLP is (often) embarrassingly parallel”. What you may not know is that this is not just him using colorful language but the actual proper term. Most tasks in NLP can be broken down to ridiculously small units and then put back together. The challenges are often to build a system that is able to do just that and not mess it up if something breaks in the middle of the process.
I often remember the simplicity of submitting a massive job on the SGE cluster at the university. As long as you could break down your task to a small enough unit and write a script that reads and writes based on parameters, you could parallelise horizontally to close to 1000 CPU cores (that was before GPUs were big 😅). Ever since I moved to industry I’ve been using other more sophisticated approaches to the same problem, e.g. a queue architecture using Kafka with worker layers on both sides, or an autoscaling microservice on a Kube cluster with the data IO and requests being parallelised locally. They are good approaches but tedious. Setting up a queue architecture is not something a data scientist could typically do in an afternoon even with docker. And writing a microservice always needs testing, setting up, and deploying, and it’s very frustrating if you need to keep tinkering with it.
A solution for lazy scientists
These constraints have been bothering me for a while and I finally sat down and did something about it. Planchet consists of a data processing manager and a client that take a different, slightly lazy approach to scaling up data processing. The way I think about it is as a data IO microservice. Kind of like a database but it also automatically keeps track of your experiments. The weak place where the microservice approach often fails is in the data management phase at the end. So I designed Planchet to handle reading and writing the data while leaving the user to decide how they want to organise the processing. This gives the user the freedom to write a script locally and just very crudely open ten terminals and run it in each one. Of course, you can use it in more sophisticated ways, but I wanted to cater to my lazy self who would be very happy to do just that.
How does it work?
The Planchet service runs on a machine that has access to the data you want to process. It manages processing jobs which have three main elements: a reader, a writer, and a ledger. The reader and the writer take care of IO while the ledger keeps track of what was read and sent out for processing and what was returned and written. Currently, this is all kept in a Redis instance with enabled persistence (so you don’t lose it if your server 🔥).
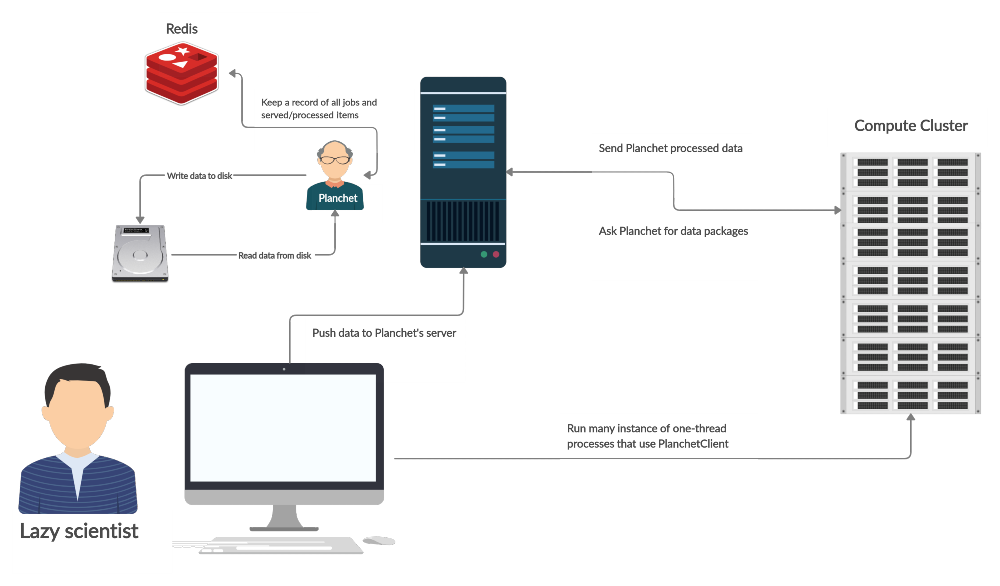
There are two standard data formats supported at the moment: CSV and
JSONL. However, the system is designed with extensibility in mind so if you
need something specific, all you need to do is add a reader and/or a writer
class in plachet.io. There are some constraints on the input/output types
but I am thinking about how to do this in a more general way at the moment.
On the client side the process is controlled using HTTP requests, and the data is sent back and forth in JSON format. The reason I thought a client may be necessary because I expect that the server may be busy at times (see below why) and auto-retrying is a great convenience feature.
A practical example
So how does this work in practice? I will go through
the example from the repo.
Let’s say that we want to tag the named entities in a ton of news headlines.
We can use the
Prodigy data
and clone it many times to create a big dataset in Planchet’s data directory.
If you’re running Planchet in a docker container, that is a directory that’s set
in your docker-compose.yml (note that the path that Planchet needs in this
case may differ from the path on the host machine); if you’re running it
directly on the “bare metal” (i.e. non-docker), then Planchet has the same
access rights to directories as the user running it.
Here’s how to set up the server side of this practical example directly on the bare metal 🧸🤘:
git clone https://github.com/savkov/planchet.git
cd planchet
mkdir data
wget https://raw.githubusercontent.com/explosion/prodigy-recipes/master/example-datasets/news_headlines.jsonl -O data/news_headlines.jsonl
python -c "news=open('data/news_headlines.jsonl').read();open('data/news_headlines.jsonl', 'w').write(''.join([news for _ in range(200)]))"
export PLANCHET_REDIS_PWD=Str0ngPa55w0rd%%!
make install
make install-redis
make run
Planchet will now run on port 5005 on your server. Note that the redis password is something you must set yourself. Best if you just set an environment variable that you can refer to consistently. Note that you can use another redis instance but it may not have persistence enabled.
Next, we will set up a processing script on the client side and run several
instances in parallel. You can download the worker.py script from
here. To prepare, run the following in your
client side shell:
pip install planchet spacy namegenerator
python -m spacy download en_core_web_sm
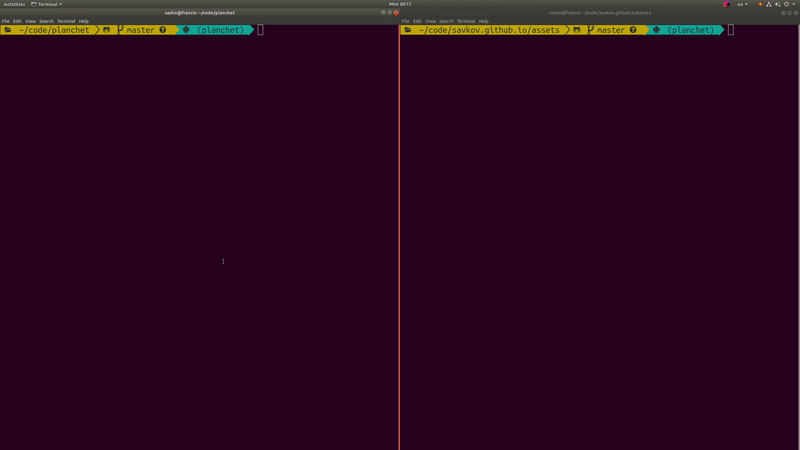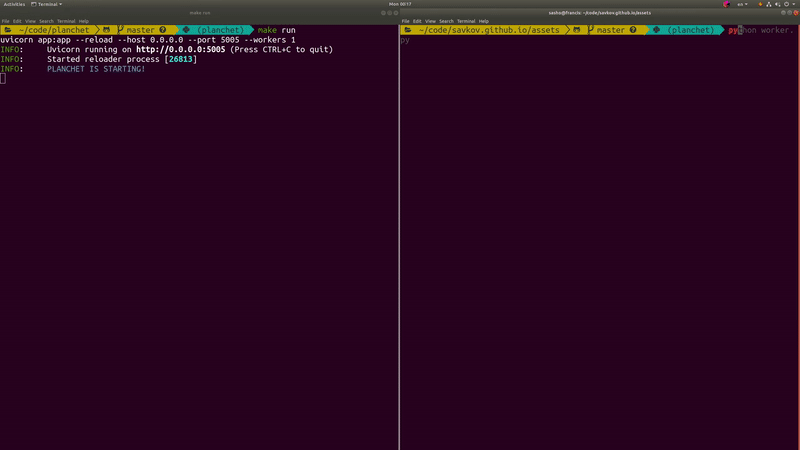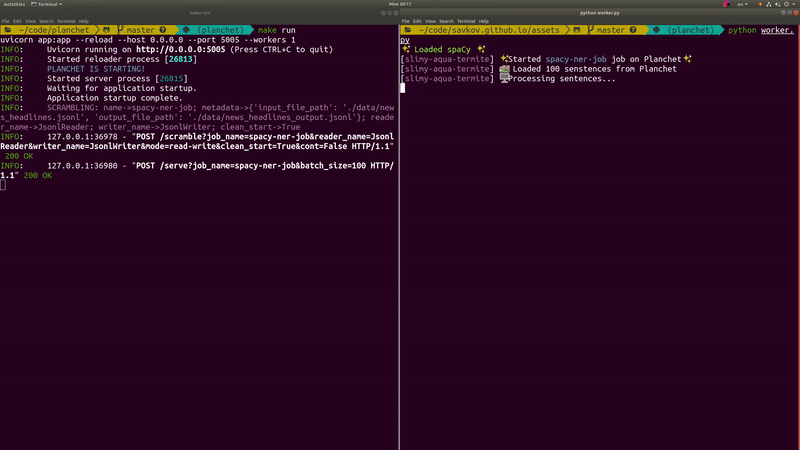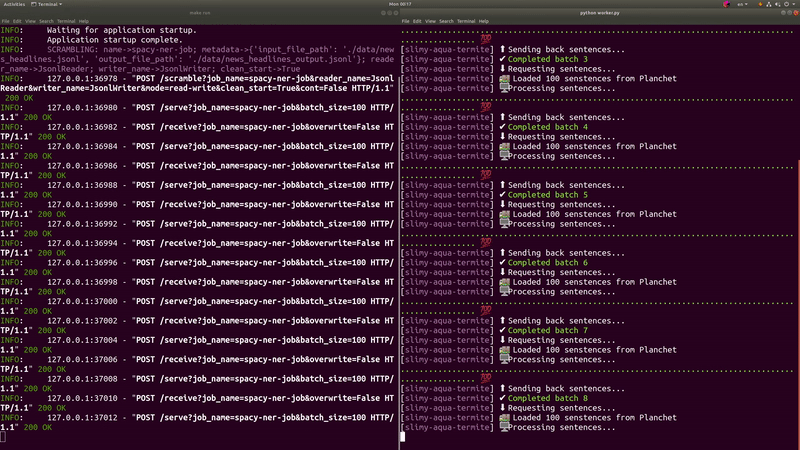
python worker.py
If everything goes well you should see something like this…
Now let’s go through what the script does in more detail. Bear in mind that I’ve
removed some of the clutter to make this easier to read. Our script is reading
news headlines from Planchet, processing the text with
spaCy and writing down the entities under a new key entities. First, we create
a client object and a spaCy object to do the processing.
client = PlanchetClient(URL)
nlp = spacy.load('en')
Then we declare the parsing function that simply takes the entities from the
English object in spaCy and transforms them into a list of dictionaries.
def parse(text):
try:
doc = nlp(text)
except Exception as e:
return []
return [{'text': ent.text, 'label': ent.label_} for ent in doc.ents]
Now, we are ready to start our job using the client and specifying JSONL readers and writers as well as metadata with the input and output files.
job_name = 'spacy-ner-job'
metadata = {
'input_file_path': JOB_INPUT_FILE,
'output_file_path': JOB_OUTPUT_FILE
}
# starting up the processing job
response = client.start_job(job_name, metadata, reader_name='JsonlReader',
writer_name='JsonlWriter')
Finally, we request a batch of items to process and start processing and requesting new batches while the requested batch doesn’t come empty.
# loading an initial batch of sentences
sentences = client.get(job_name, N_ITEMS)
# processing until exhausted
while sentences:
records = []
for id_, record in sentences:
text = record['text']
ents = parse(text)
if not ents:
continue
new_record = {
'text': text,
'entities': ents
}
records.append((id_, new_record))
client.send(job_name, records)
sentences = client.get(job_name, N_ITEMS)
Limitations
The first and most important limitation of Planchet is that it is not a production tool. Conceptually, it takes the wrong approach for the sake of solving a problem that does not exist in production environments.
The second very important limitation is that Planchet is very bad at security. It basically gives quite generous access to your system through the service. This is somewhat mitigated by the use of a docker container, i.e. nobody cares if a container is compromised. But if you are running Planchet on the bare metal you should definitely consider running it under a restricted user.
There are other limitations that are of lesser importance and should be solved in time as the project develops. For example, Planchet is like a grumpy teenager at the moment – it does things but if you get something wrong, it just grunts and slams the door in your face. Basically, you need to go to the server logs to understand if something strange is happening. There is also the issue of users which should hopefully arrive sooner rather than later. And the issue of storing too many things on Redis, i.e. I need to re-think the paradigm of creating a key-value pair for each processed item.
Final words
In conclusion, I want to urge those of you who find this interesting to go and test it for yourself; and maybe report your issues if you find any. If you found it useful, give us a tweet about it – we love internet points!
